

新時代を切り拓く生成AIの現状と課題
2023年7月19日、東京大学次世代知能科学研究センター連続シンポジウムの第15回がオンラインで開催されました。今回は「生成AIは世の中をどのように変えるのか?」というテーマで行われました。この記事では4名の登壇者の発表を要約することを通して、生成AIの現状と課題を多角的に捉えたうえで生成AI時代の行く末を予見します。
急速に広がる生成AI技術
第15回シンポジウムは司会の松原仁教授の趣旨説明の後、1人目の登壇者である東京大学大学院情報理工学系研究科所属の鶴岡慶雅教授が「生成AIとは何か」と題して、生成AIの技術的概要を発表しました。
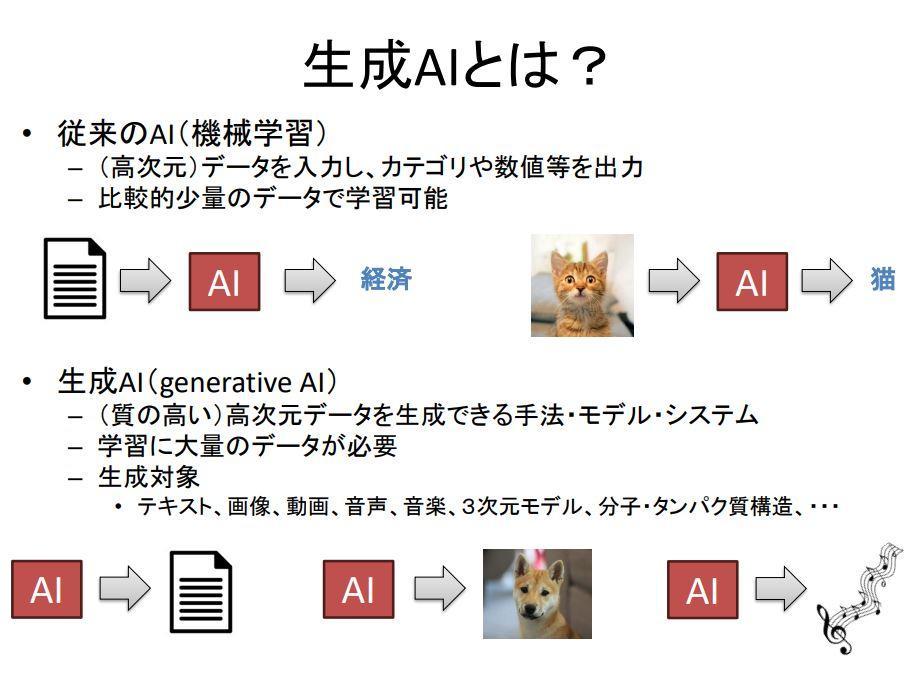
はじめに鶴岡教授は、生成AIの特徴を従来のAI(機械学習)との対比で説明しました。従来のAIは文章や画像を入力すると、「経済(に関する文章)」や「猫」といった情報としては非常に簡単なカテゴリー名などを出力するものでした。対して生成AIは長文のテキストや高精細な画像といった非常に複雑な構造をもつ情報を出力します。従来のAIと生成AIの違いは、出力に顕著に現れるのです。
今日の生成AIを代表するのは、OpenAIが2022年11月末に公開した対話型AIのChatGPTです。このAIは、プロンプトと呼ばれるユーザの指示にしたがって文章を生成するほか、オセロゲームのコードを生成したり、機能拡張するツールの一種であるプラグインCode Interpreterを使えば、データ分析や作図が出来たりします。
ChatGPTの主な出力はテキストなので、言語生成AIに分類されます。このカテゴリーのAIにはChatGPTと同様に汎用的な言語処理を実行できるBingAIやBardがあり、検索特化型としてPerplexity AIなどがあります。最近ではオープンソースのLlama 2などもあり、それらをまとめると以下のスライドのようになります。

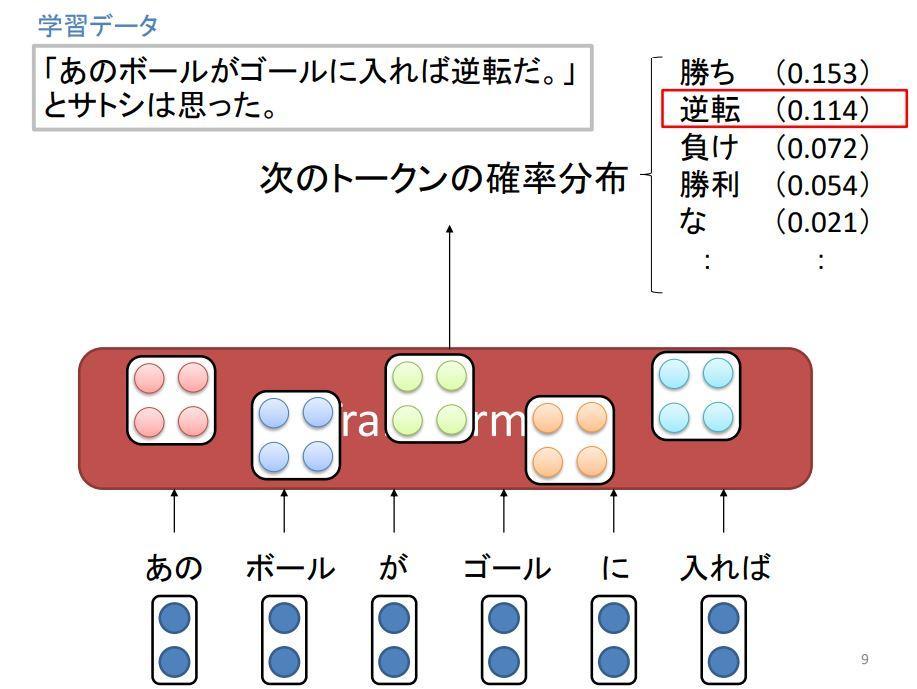
言語生成AIには、Transformerと呼ばれるニューラルネットワークが使われています。Transformerに学習データを与えると、そのデータにふくまれるトークン(テキストの処理上の単位)の前後関係を学習します。学習後にTransformerに任意のテキストを入力すると、その入力に後続する確率の高いトークンを予測できるようになります。一般に学習データが多いほど、言語生成AIの精度は高くなります。
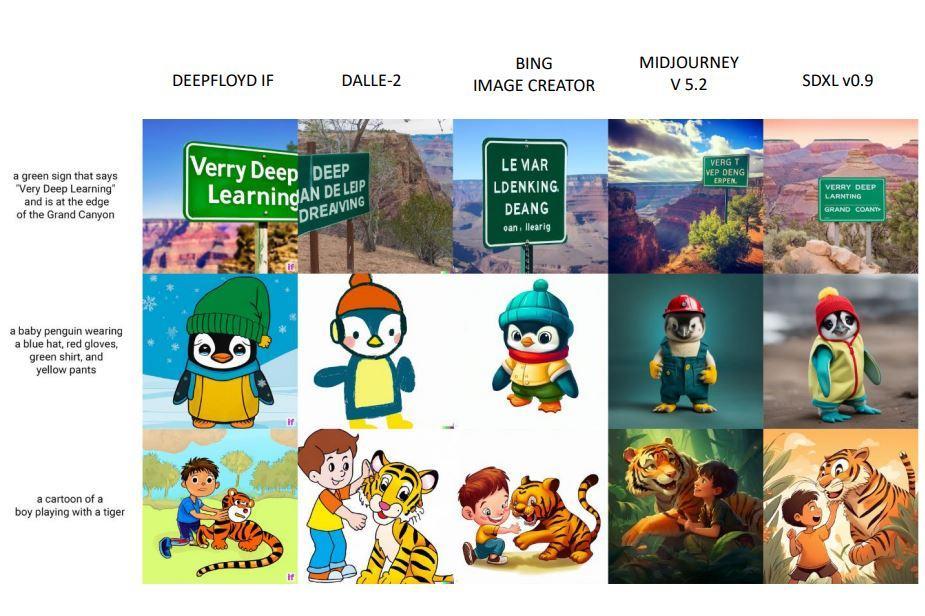
言語生成AIとともに普及している生成AIには、任意のテキスト入力に対して、そのテキストの内容に合致する画像を生成する画像生成AIがあります。近年普及しているStable Diffusionなどには、拡散モデルという技法が使われています。この技法は、粒子の拡散のような物理現象を画像生成に応用したものです。こうした画像生成AIは以下のスライド画像のように多数公開されており、最近では自然言語で画像の編集を指示できるCM3Leon(カメレオン)のようなAIも発表されています。
任意のテキスト入力に対して、その入力に合致する動画を生成する動画生成AIや、テキストを入力すると音楽を生成する音楽生成AIもあります。前者にはPIKA LABSが発表したAIやGoogleが発表したphenaki、後者にはMetaが発表したMusicGenがあります。

以上のような生成AIを活用して可能となることは、多岐に渡ります。各種生成AIを使えば、個人で映画や音楽、ゲームが制作できるようになるほか、文書の要約をはじめとする各種オフィスワークを効率化できます。さらには法律相談、コーディング、医療診断、教育のような専門家が提供してきた各種サービスを安価に利用できたり、専門家が生成AIの支援を受けられるようになります。


最後に鶴岡教授は、以下のスライドにまとめたような生成AIのリスクを指摘して発表を終えました。
OpenAIに見る生成AIビジネスの仕組み
2人目の登壇者である株式会社オルツ所属の西川仁氏は「生成AIとビジネス」と題して、事業から見たOpenAIの考察と生成AIビジネスの仕組みについて発表しました。
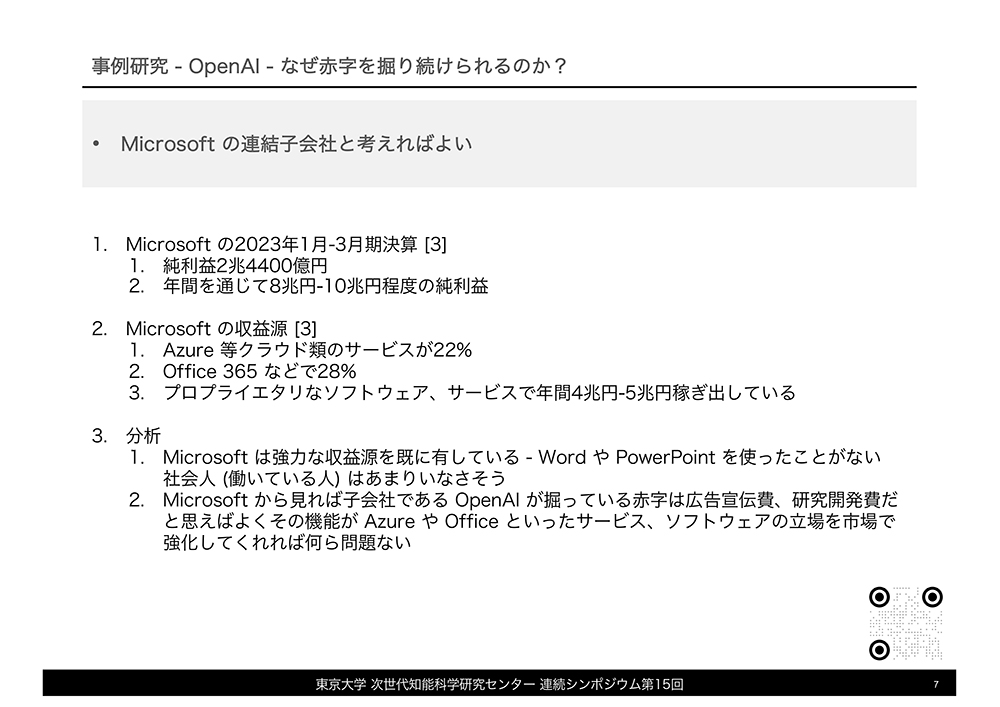
西川氏は生成AIをビジネス的観点から考察するにあたり、ChatGPTを提供するOpenAIを事例研究対象としました。複数の情報を総合すると、同社はその知名度に反して生成AIビジネスを黒字化できていません。具体的には2022年だけでも730億円の赤字を計上しており、赤字幅は今後広がると予想されます。

赤字が続くにも拘わらずOpenAIが事業を継続できるのは、Microsoftが同社を資金支援しているからです。Microsoftが資金支援するのは、OpenAIの技術を自社製品に組み込むことでユーザの囲い込みを強化するためです。そうした思惑は、例えばGPT-4を活用したBing AIやAI技術を統合したMicrosoft 365 Copilotに現れています。そして、ユーザを強固に囲い込んでから使用料等から収益を上げれば、長期的にはOpenAIの赤字は帳消しにできるのです。こうしたOpenAIの事例研究からわかるのは、生成AIビジネスを黒字化するには時間がかかり、黒字化するまでに生成AI以外からの収益を確保する必要があることです。
OpenAIの事業分析に続いて、西川氏はAI市場のエコシステム概観を示しました。同市場は物理的基盤から各種アプリにいたる複数のレイヤーから構成されており、物理的レイヤーからインフラ層、基盤モデル層、ミドルウェア層、アプリケーション層となります。それぞれのレイヤーで事業を行うためには、異なる技術とリソース、そしてレイヤーの特徴に合ったビジネス戦略が求められます。
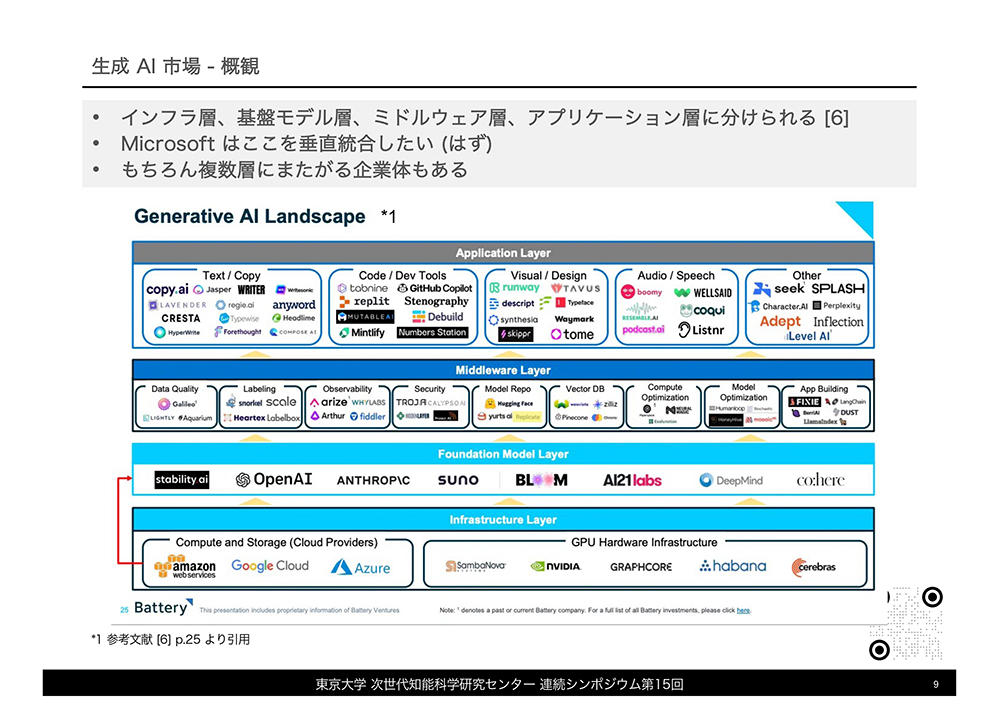
OpenAIは、基盤モデル層に位置付けられるChatGPTで名声を得ました。ChatGPTの普及には前述したMicrosoftによる資金支援に加えて、同AIの前身にあたるGPT-3の洗練が必要でした。GPT-3は人間が書いたかのような文章を生成できましたが、一般ユーザが使い易いものではありませんでした。こうしたGPT-3に対してOpenAIが人間の好むような文章を生成できるように強化学習したうえで、対話型インターフェースを与えたことで誕生したのがChatGPTでした。ChatGPTが普及したのは、このAIが技術的に卓越していたからと言うよりは、一般ユーザが使い易いかたちで提供できたProduct Marekt Fitが実を結んだからと考えられます。

前述したように今後生成AIに関連するビジネスを実施する場合、参入するレイヤーによってビジネス戦略が異なります。OpenAIのようにインフラ層や基盤モデル層で事業を行う場合、大規模な計算資源と人的資源が必要となるうえに、早期の黒字化は期待できません。また、AIの使用料といった黒字化するための戦略を明確化しなければなりません。アプリケーション層で事業を行う場合、ユーザのニーズに合ったアプリケーションのコンセプトが不可欠です。この場合、開発資金はアプリケーション開発できる程度で充分ですが、使用する基盤モデルの使用料変更など、外部のリソースに依存している事業上の脆弱性、事業への影響を考慮する必要があります。

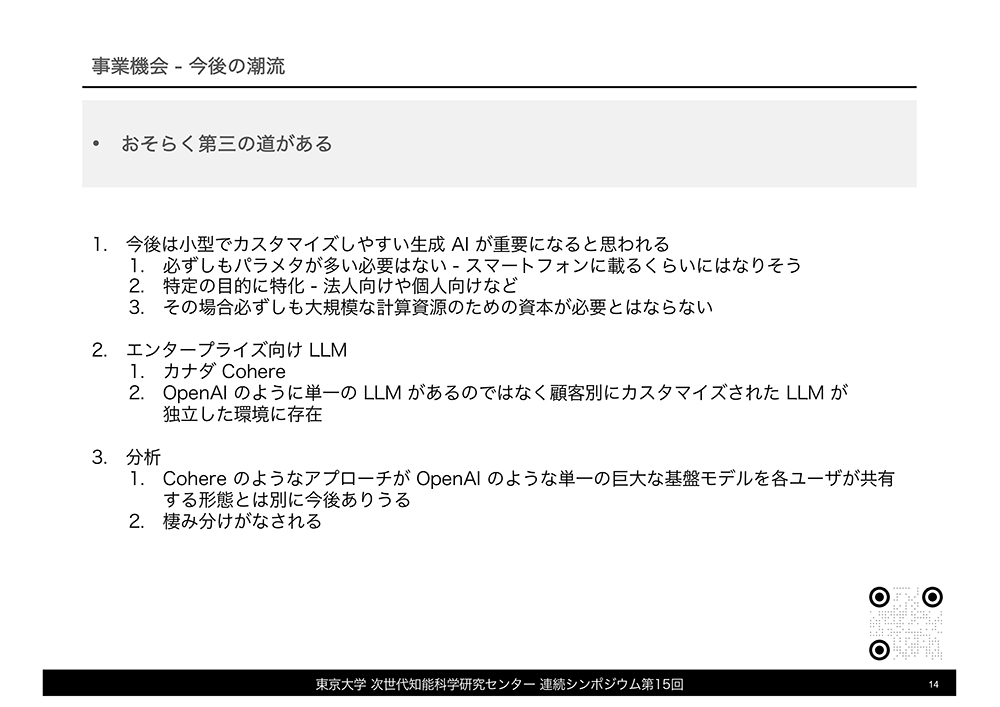
西川氏は、今後の生成AIビジネスの潮流についても話しました。1つ目の潮流は、GPT-4のような大規模な生成AIに対抗して、スマートフォンで動作するような軽量な生成AIの台頭が挙げられます。2つ目は、カナダ企業Cohereのような顧客企業ごとにカスタマイズされた生成AIを提供するビジネスです。既存の大規模な生成AIに加えてこうした新たな潮流が合流することで、複数の生成AIビジネス形態による棲み分けが進むだろう、と述べて同氏は今後の生成AI市場動向を総括しました。
システム体制ごとに異なる生成AI運用
3人目の登壇者はSTORIA法律事務所所属弁護士の柿沼太一氏が「生成AIを利用する際に法的に注意すべきこと」と題して、生成AI運用体制に則した社内ルール作りについて発表しました。
はじめに柿沼氏は、ChatGPTをはじめとする大規模言語モデル(Large Language Model:以下、「LLM」と略記)を使ってアプリやシステムを提供するビジネスに認められる3つのレイヤーを図示したスライドを示しました。示されたレイヤーとは、以下のようなものです。
- LLM開発レイヤー:ChatGPTのようなLLMを開発する企業が属するレイヤー。学習データの収集時には、著作権及び個人情報保護法等に留意する必要がある。
- LLM活用アプリ・サービス開発レイヤー:LLMを活用したアプリやシステムを開発する企業が属するレイヤー。
- LLM利用レイヤー:LLMアプリ・サービスを利用する企業が属するレイヤー。とくにLLMアプリ・サービスの入出力データの内容に留意する必要がある。
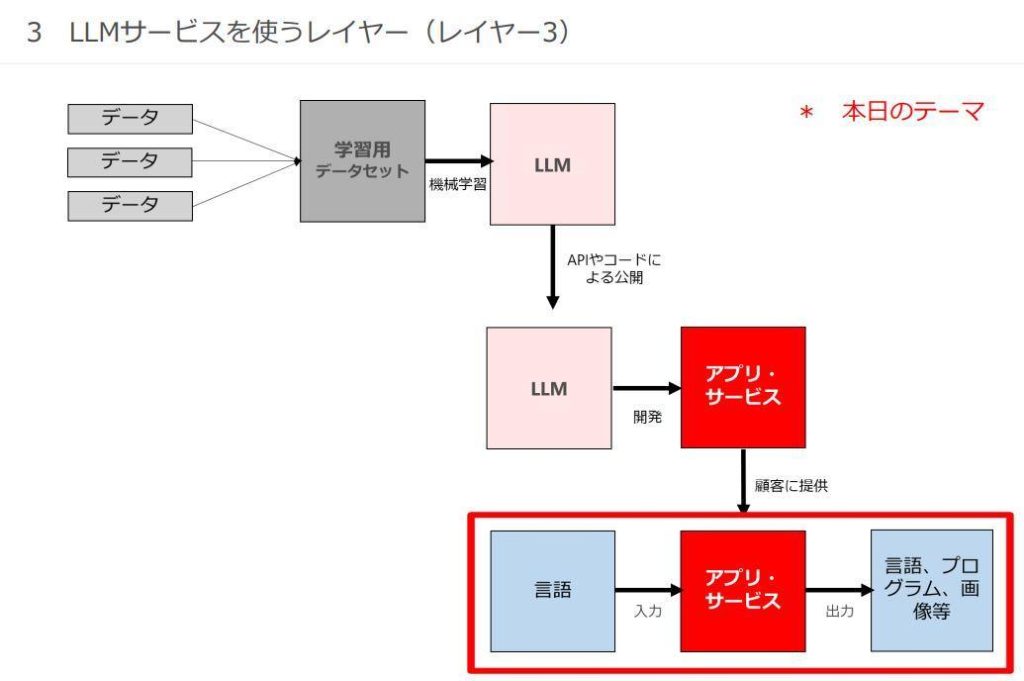
以上のようなレイヤーを示したうえで、柿沼氏は今回の発表ではLLM利用レイヤーに絞って、企業におけるLLM活用に関するルール作りについて話しました。LLM活用ルールに関しては、日本ディープラーニング協会が2023年5月1日に当該ルールの雛形となる「生成AIの利用ガイドライン」を発表しています。同ガイドラインは5万回以上ダウンロードされましたが、実際にLLMアプリ・サービスを運用するには同ガイドラインだけでは不十分と同氏は指摘します。

LLMアプリ・サービスを活用するには、以下のような3つの観点に応える対応とルール作りが必要と柿沼氏は指摘します。
- 観点1:生成AIの強みを引き出す使い方を定める。
- 観点2:(ハルシネーションのような)生成AIの限界を知る。
- 観点3:他社の権利侵害、法令違反にならない使い方を定める。
観点1と観点2については、LLM活用業務に適したLLM運用体制を選定することで応えられます。観点3については、LLM活用ガイドラインを社内で制定することで解決できます。
LLM運用体制の選定について、柿沼氏は以下のような3つの体制を挙げました。
- 外部サービス利用:社外製のLLMとLLMシステムを活用する体制。LLMとLLMシステムを提供するした企業がそれぞれ異なる場合と、単一の企業が両方を提供する場合に細分化される。ChatGPTの活用は後者に該当。
- 自社システム利用:自社開発したLLMとLLMシステムを運用する体制。
- 自社システム+外部システム利用:外部LLMをAPI等で利用するが、LLMシステムは自社製を利用する体制。
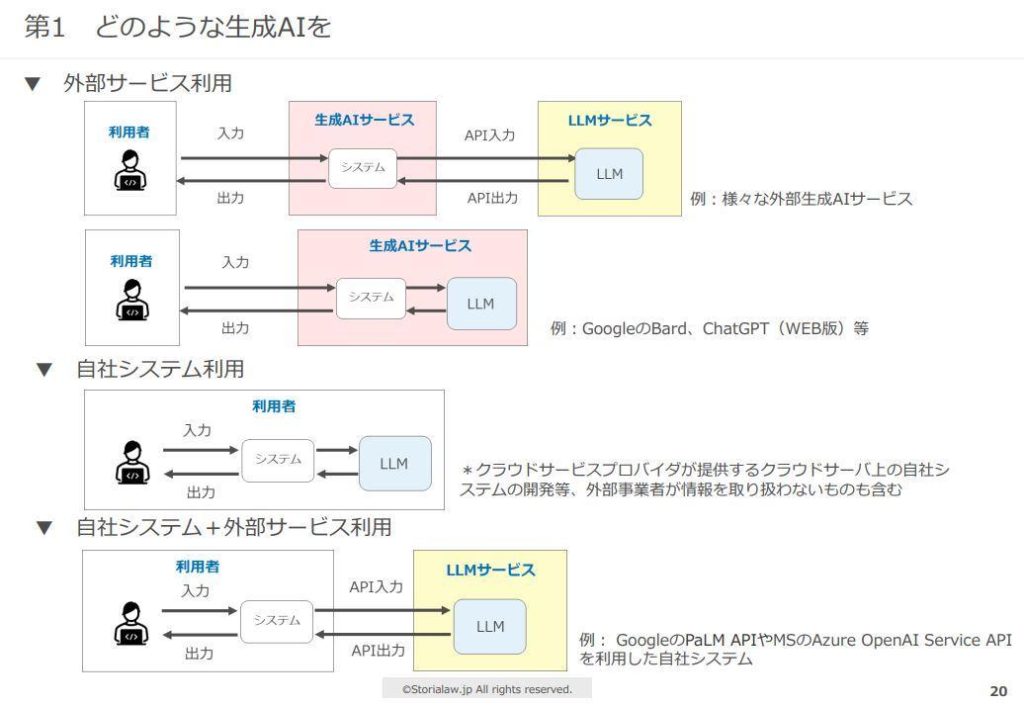
以上のようにLLMシステム運用体制の類型を確認したうえで、柿沼氏はLLMシステム運用に際する注意事項を以下のようなスライドを用いて列挙しました。注意事項は、LLMへのデータ入力とLLMの生成物に関わるものに大別されます。LLM運用体制によって対応が変わるのは、データ入力に関する注意事項です。他社から得た機密情報あるいは自社のそれの扱いに関しては、外部サービス利用より自社システム利用のほうが機密性を保てます。

柿沼氏は、もっとも問い合わせが多いのはAI生成物に関する著作権をめぐる問題だと述べました。この問題についてはアメリカでは訴訟が起こっているものも、日本では訴訟に至っていないので法的に確かなことはまだ言えない段階にある、との見解を示して同氏は発表を終えました。
生成AI時代の新たなステークホルダーとガイドライン
4人目の登壇者は東京大学未来ビジョン研究センター所属の江間有沙准教授が「生成AI特有の社会課題はあるのか」と題して、生成AIをめぐる社会問題について考察しました。
江間准教授は生成AI特有の問題を特定するにあたり、対話型AIのChatGPTとBardに聞いてみて得られた回答を示しました。その回答とは「品質の不安定性」「プライバシーと倫理の問題」「偏見や不平等」「偽造と信頼性の問題」というものでした。このうち「偽造と信頼性の問題」以外の3つはAI全般に共通するものですが、「AIが生成したものをAIが学習する」という事態は生成AIが登場することで特に注目を集めています。また、「偽造と信頼性の問題」は、偽情報や偽画像の問題として現在、政策的な課題としても早急な対応が求められています。

以上の4つのほかにも生成AIが引き起こす問題として、生成AIによる仕事の代替によって生じる失業問題、回答がAIで生成されることで再考を余儀なくされる教育現場の問題、AI生成物に関する著作権をはじめとする法整備、さらには文章や音声を偽造することで起こる犯罪の巧妙化などが挙げられます。

江間准教授は、対話型AIのインターフェースについても考察しました。対話型AIはインターフェースをチャット形式にしたことにより、一般ユーザが親しみやすいものとなって普及したと考えられます。この種のAIは丁寧な言葉遣いであることも特徴であり、間違えた時には平身低頭の姿勢で謝るという特徴があります。こうした特徴について、間違えた時に深く謝っておけば、ユーザの信頼を失わずに済むと開発陣が考えた結果ではないか、と同准教授は指摘しました。

江間准教授は、生成AIをめぐる責任の所在についても考察しました。この考察においては、2019年に総務省が発表した「AI利活用ガイドライン」を参考にしています。既存の「国際的な議論のためのAI開発ガイドライン案」「AI・データの利用に関する契約ガイドライン」「AI利活用ガイドライン」といったガイドラインはAI開発者とAI提供者を対象としていることがわかります。
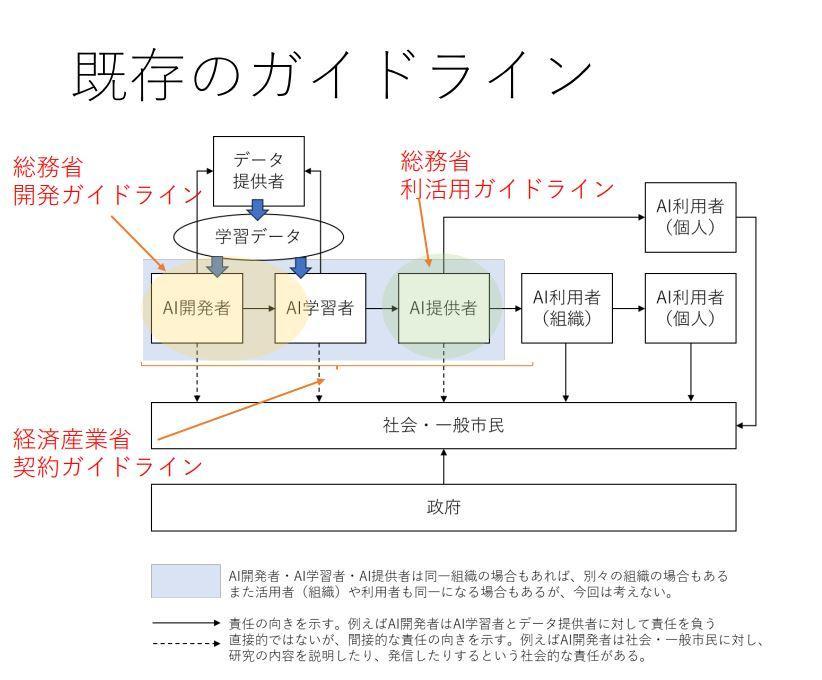
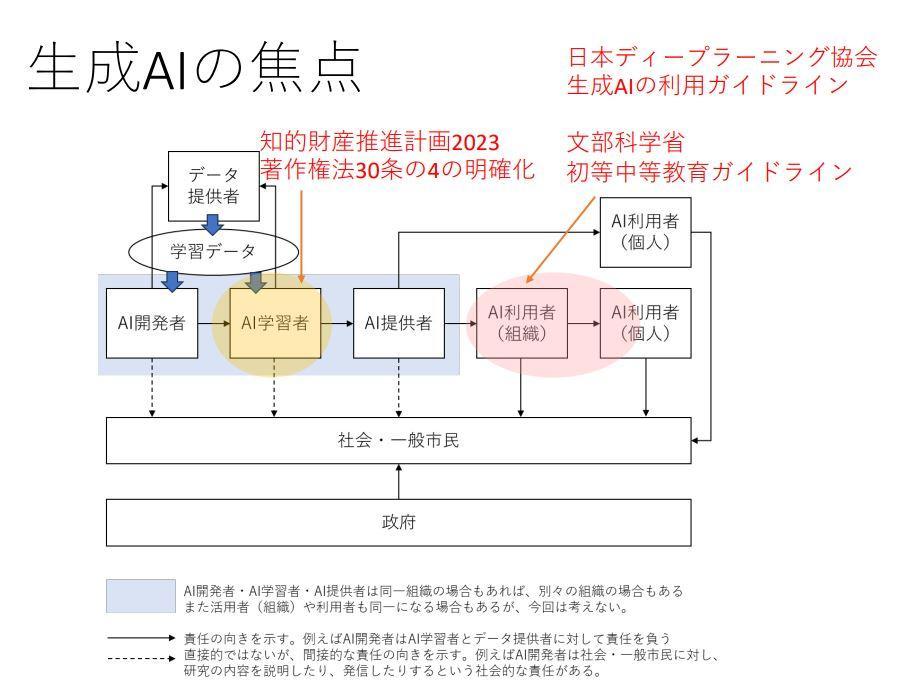
生成AIが一般に普及すると学習データをめぐる著作権や、生成AI利用者による著作権侵害や偽情報の流布といった問題が顕著になってきました。学習データをめぐる問題は文化庁が著作権法30条の4の明確化をふくむセミナーを開催したり、教育現場における生成AI利活用については文部科学省が「初等中等教育段階における生成AIの利用に関する暫定的なガイドライン」を発表したりして対応しています。こうした対応をステークホルダー図にマッピングすると、以下の画像のようになり、ガイドラインもより利用者側まで拡張しているということがうかがえます。
江間准教授は生成AIの可能性と懸念について、以下のような4つの観点から整理して発表を終えました。
- 効率性:生成AIは多くのタスクの遂行効率を向上させるが、善用と悪用の両方に活用できてしまう。
- 品質:学生に生成AIを活用してレポートを作成させたところ、学生全員のレポートの品質が向上した事例が報告されている。こうした品質向上は内容の均一化に向かうのか、それとも多様化に向かうのか、という問題は今後の生成AI活用の課題となる。
- クリエイティビティ:望ましい生成AIの表現とは人間が想定した通りの出力なのか、それとも想定外のそれであるべきなのか、今後の議論が待たれる。
- 共存:生成AIは、人間の相棒としてあらゆる活動を支援するようになるだろう。こうした人間と生成AIの共存は安心を人間のもたらす可能性がある一方で、人間が生成AIに依存してしまうリスクもある。

江間准教授の発表後、司会の松原仁教授と登壇者4名によるパネルディスカッションが行われました。ディスカッションで語られた興味深い見解の一部を箇条書きにすると、以下のようになります。
- (松原教授の「生成AIがAI生成物を学習すると、間違った方向に学習する懸念はないのか」という質問に対する鶴岡教授の回答)会話や画像に関して、生成AIがAI生成物を学習すると性能が劣化してしまう。というのも、ゲームだと勝敗という最終的なフィードバックから学習の方向を修正できるが、会話や画像からは明確なフィードバックを得られないので間違った方向に学習が進んでしまうからである。
- (以上の松原教授の質問に関連して西川氏発言)LLMどうしが会話し続けても「良い会話」や「生産的な会話」と判定する基準があいまいなので、LLMの性能は向上しない。こうしたなか生産的な会話の基準として、タスクαを実行するLLM①とLLM②が会話する状況を設定したうえで、タスクαの遂行に向上が認められれば、その会話を生産的と見なす、というアプローチが考えられる。タスクαには商品の売上、ウェブ広告のクリック数など明瞭に計量可能なものが望ましい。
- (松原教授の「AIが生成したコンテンツに著作権は発生するのか」という質問に対する柿沼氏の回答)AI生成物の活用は、不具合画像に関する合成データのような先例がある。現状ではAI生成物には著作権が発生しないので、AI生成物の品質が学習データに活用できる程度に向上すれば、むしろ生成AIの研究開発に役立つと考えられる。
- (視聴者からの「生成AIがより精緻な会話ができるようになるには、どのような技術革新が必要なのか」という質問に対する鶴岡教授の回答)現在のLLMは長いコンテキストを処理できないという限界がある。この限界は、処理できるコンテキスト量(トークン量)を増やせば解決するだろう。
- (以上の鶴岡教授の回答に関連して西川氏発言)生成AIに長期記憶を保持させる方法として、長期記憶を生成・保持するモジュールをアーキテクチャに実装する方法と、会話履歴をデータベースに保存して必要に応じて会話中でデータベースを参照する方法の2通りが有力である。
- (松原教授の「プロンプトを使って小説を書いた場合、プロンプト入力者は小説に対する著作権を持つのか」という質問に対して柿沼氏の回答)プロンプト入力者が出力に対して著作権を持つかどうかは、プロンプトとプロンプト出力の関係に依存する。プロンプトがプロンプト出力の要約になっている場合、プロンプト入力者はプロンプト出力に対して著作権を持ちうる。対してプロンプトがプロンプト出力のあらすじになっている場合は、著作権は発生しない。つまり、プロンプト出力に対するプロンプトの寄与度が大きければ著作権が発生し、反対に寄与が小さければAIが出力したものとなり著作権は生じない。
- (視聴者からの「LLMがときどき嘘をつくのは、ユーザのリテラシー向上から見ればファクトチェックの重要性を認識できるので、むしろ好ましいのではないか」というコメントに対して江間准教授発言)LLMのハルシネーションは、確かにAIの神格化に歯止めをかける効用がある。問題なのはハルシネーションを判別できない状況で、LLMを使うようなケースである。例えば、機械翻訳を使ってユーザが理解できない言語に翻訳したうえで、その言語を母国語としている人とコミュニケーションする場合、「機械翻訳を使っているので間違っている可能性がありますが」と注意を入れたうえで、それでも相手の母国語でメールを送るという選択肢が可能となっている。嘘をつくかもしれないけれど、それを承知したうえでコミュニケーションのサポートツールとして使うという場面が今後は増えてくるのではないか。
- (生成AIがAI生成物を学習する際の問題について江間准教授発言)生成AIは(SNSの加工顔画像のように)すでに加工されたデータを学習しているので、必ずしも現実や真実を反映していない場合もある。生成AIの出力と現実との関係は、今後考えるべき問題だろう。
- (LLMの誤答に関して鶴岡教授発言)OpenAIは、ChatGPTに自身の回答の正確性をある程度チェックする処理を実装することも可能だったはずである。しかし、そうした処理を入れると処理時間が長くなったり、料金を高く設定する必要があったりするので、ビジネス上の判断でそのような機能を実装しなかったのだろう。
- (「1年後の生成AIはどのようになっているか」という松原教授の質問に対する江間准教授の回答)。普及すると同時に格差が生じているかもしれない。そうした格差のひとつには、有料の生成AIを利用するかどうかで生じる課金格差がある。もうひとつには、生成AIから所望の出力を得るために求められるプロンプトエンジニアリングをめぐるスキル格差がある。
- (以上の松原教授の質問に対する西川氏の回答)特定のユースケースにおいては、プロンプトエンジニアリングを駆使しなくても所望の出力が得られるように改善されると予想している。長期的にはAIを使えるかどうかで、ある種の社会階層が生じるかも知れない。
- (以上の質問に対する柿沼氏の回答)一部の巨大AI企業が繁栄する一方で、そうした企業がカバーしていない市場の隙間が小さくなっているような印象がある。
- (以上の質問に対する鶴岡教授の回答)AI技術の向上によって高品質の製品・サービスが利用しやすくなる一方で、社会インフラと化すAI技術が一部の巨大AI企業に独占される懸念はある。
以上のようなシンポジウムをまとめると、生成AIの台頭はインターネットやスマホの普及に匹敵する重大イベントだということでしょう。生成AIは技術的に日進月歩であり、その市場も成長している一方で、法整備や利活用に関するリテラリーに大きな課題を抱えています。こうした状況下において重要なのは、開発者から一般ユーザにいたるまでのすべてのステークホルダーが当事者意識を持ったうえで、課題の解決に向けて議論を深めていくことではないでしょうか。
Writer:吉本幸記